6. Повышение производительности¶
Один из известных ресурсов повышения производительности - выявление и использование параллелизма на уровне элементарных операций (устоявшийся термин ILP = Instruction-Level Parallelism). Для АПП «Эльбрус» параллелизм выражается в машинном коде явным образом в виде Широких Команд (ШК), а задача обнаружения и эффективного использования ILP возлагается на компилятор - этот принцип характерен для всех известных процессоров VLIW. Далее будет показан ряд решений, реализованных в АПП Эльбрус, направленных на выражение, обнаружение и увеличение ILP. Ознакомившись с материалом, читатель сможет видеть в коде результаты применения этих решений и регулировать их работу с помощью опций оптимизирующего компилятора и/или модификации исходных текстов оптимизируемых программ.
6.1. Планирование кода¶
Рассмотрим простейший пример функции на языке C и соответствующий ей ассемблерный код:
int f(int a, int b, int c)
{
int x = a * b + c<<3;
int y = b * c + a<<4;
return x + y;
}
f:
muls %r0, %r1, %r7 !0 ! _t0 = a * b
shls %r2, 0x3, %r8 !1 ! _t1 = c<<3
adds %r7, %r8, %r5 !2 ! x = _t0 + _t1
muls %r1, %r2, %r9 !3 ! _t2 = b * c
shls %r0, 0x4, %r10 !4 ! _t3 = a<<4
adds %r9, %r10, %r6 !5 ! y = _t2 + _t3
adds %r5, %r6, %r0 !6 ! _retval = x + y
return %ctpr3 !7 ! prepare return
ct %ctpr3 !8 ! return
В примере для простоты оставлены только арифметические операции и операции передачи управления.
Если попробовать собрать из приведенного ассемблера машинный код и исполнить его на потактовом симуляторе процессора, то можно наблюдать следующее:
все операции заняли по одной широкой команде, и как следствие по одному такту, несмотря на наличие независимых вычислений, которые можно было бы запустить одновременно, пользуясь ресурсами широкой команды;
некоторые широкие команды выполняются с задержками в несколько тактов; это вызвано тем, что некоторые операции требуют нескольких тактов для выработки результата, и конвейер процессорного ядра, пытаясь исполнить команду с неподготовленным аргументом, пропустит несколько тактов.
f:
muls %r0, %r1, %r7 !0 ! _t0 = a * b
shls %r2, 0x3, %r8 !9 ! _t1 = c<<3
+4 такта
adds %r7, %r8, %r5 !10 ! x = _t0 + _t1
muls %r1, %r2, %r9 !11 ! _t2 = b * c
shls %r0, 0x4, %r10 !20 ! _t3 = a<<4
+4 такта
adds %r9, %r10, %r6 !21 ! y = _t2 + _t3
adds %r5, %r6, %r0 !22 ! _retval = x + y
return %ctpr3 !23 ! prepare return
+6 тактов
ct %ctpr3 !30 ! return
Как видим, оба фактора отрицательно сказываются на производительности при исполнении этого кода. Перед компонентой компилятора, занимающейся планированием кода, стоит задача обнаружить и выразить в широких командах параллельность на уровне операций в пределах линейных участков кода, и одновременно с этим при размещении очередной операции в широкой команде выдержать длительности операций-предшественников, которые вырабатывают ее аргументы.
f:
{ ! T=0
return %ctpr3 !0 ! prepare return
muls,0 %r0, %r1, %r7 !0 ! _t0 = a * b
muls,1 %r1, %r2, %r9 !0 ! _t2 = b * c
}
{ ! T=1
nop 4 !1 ! явная задержка
shls,0 %r2, 0x3, %r8 !1 ! _t1 = c<<3
shls,1 %r0, 0x4, %r10 !1 ! _t3 = a<<4
}
{ ! T=6
adds,0 %r7, %r8, %r5 !6 ! x = _t0 + _t1
adds,1 %r9, %r10, %r6 !6 ! y = _t2 + _t3
}
{! T=7
adds,0 %r5, %r6, %r0 !7 ! _retval = x + y
ct %ctpr3 !7 ! return
}
Ниже приведена таблица длительностей некоторых классов операций на платформе «Эльбрус».
Операция Задержка
Int, Bitwise 1
Int_combined 2
Fp 4
Fp_combined 8
Fdivs/d 11/14
Ld L1 hit 3
Ld L2 hit 11
Ld L3 hit 40
Ld mem ~100
Cmp->logic 1
logic->logic 0.5
Cmp,logic->qual 2
Сmp,logic->ct 3
Disp->ct 5
Return->ct 6
Movtd->ct 9
fp->int +2
int->fp +0
- Int, bitwise
целочисленные операции add, sub, побитовые and, or, xor, сдвиги shl, shr, sar, расширение знака sxt и некоторые другие. Время выполнения - 1 такт: если операция стоит в такте N, ее результат готов к использованию в такте N+1.
- Int_combined
комбинированные (двухэтажные) целочисленные операции: shl_add, xor_and и т.д.
- Fp
вещественные операции сложения и умножения fadd, fmul, а также целочисленные операции mul.
- Fp_combined
комбинированные вещественные операции fmul_fadd, fadd_sub и т.д.
- Fdiv
операция вещественного деления. Длительность операции зависит от используемой разрядности (для 32 бит - это 11 тактов, для 64 бит - это 14 тактов).
Операция чтения из памяти имеет различную длительность в зависимости от уровня кэш-памяти, в которой нашлась копия читаемых данных.
Самое быстрое чтение из L1 - 3 такта, самое долгое чтение - из памяти, оно может длиться от 100 до 200 тактов в зависимости от
конкретной архитектуры процессора «Эльбрус». Планировщик всегда будет планировать чтение из L1,
если только от программиста не было подсказки не обращаться по чтению в L1.
Для операций сравнения Cmp и логических операций andp длительность определяется тем, какая операция и каким образом потребляет результат.
для потребителей вида andp задержка составляет 1 такт, причем в некоторых случаях источник andp и потребитель andp можно спланировать в одном такте (но не более двух зависимых), поэтому длина задержки andp - andp трактуется как 0.5 такта.
для потребителей - арифметических операций, исполнение которых управляется (отменяется) вычисленным предикатом, задержка равна 2 тактам;
для потребителей - операций передачи управления ct, call, branch, задержка равна 3 тактам.
Для различных операций, устанавливающих регистр подготовки передачи управления, величина задержки до операции передачи управления различается:
для статической подготовки перехода или вызова процедуры - 5 тактов;
для статической подготовки возврата из процедуры - 6 тактов;
для динамической подготовки перехода или вызова процедуры по значению числового регистра (вызовы по указателю, конструкции switch-case) - 9 тактов.
Наконец, есть дополнительный «штраф» за передачу данных между целочисленными и вещественными операциями - он составляет +2 такта к длительности операции в случае, когда операция-источник является вещественной, а потребитель - целочисленной, и +1 такт в симметричном случае: источник - целочисленная операция, потребитель - вещественная.
Нужно отметить, что дополнительный «штраф» в классе fp получают упакованные (векторные) целочисленные операции, а также операции целочисленного умножения и деления.
Таким образом, возвращаясь к рассмотренному примеру, из приведенной краткой таблицы можно увидеть, что задержка от операции muls до операции add составляет 6 тактов: 4 такта собственной длительности mul, и +2 такта передачи результата от вещественной операции до целочисленной.
6.2. Inline - подстановки¶
Под инлайном функции понимается подстановка тела функции в другую функцию. При этом происходит связь фактических параметров с подставляемыми. В результате такой подстановки исчезают затраты на время вызова процедуры, передачи параметров и возврата значения, а также возникает контекст для дополнительных оптимизаций. Иллюстрация inline-подстановки представлена на примере.
double f(double x, double y)
{
double r;
if ( x > y )
r = ( x – y );
else
r = ( x + y );
return r;
}
void g(double *p, int n)
{
int i;
for (i=0; i<n; i++)
p[i]=f(p[i],p[i+1]);
return;
}
После inline-подстановки функция f осталась бы прежней. Она не исчезает, так как она может быть вызвана и из других функций. А функция g приобрела бы следующий вид:
void g(double *p, int n)
{
int i;
for (i=0; i<n; i++)
if (p[i] > p[i+1])
p[i] = ( p[i] – p[i+1] );
else
p[i] = ( p[i] + p[i+1] );
return;
}
Можно выделить как позитивный, так и негативный эффект от inline-подстановки.
Позитив:
удаление операций вызова, возврата, передачи параметров;
в некоторых случаях контекст для других оптимизаций: упрощение вычислений, протаскивание констант, упрощение управления;
увеличение степени параллельности операций.
Негатив:
усложнение кода для отладки;
увеличение времени компиляции;
снижение hit rate для кэша команд.
Вызов функции для компилятора является барьером для оптимизации: компилятор в поиске ILP ограничен процедурой, и к тому же часто не имеет возможности переставлять операции с вызовами функций. Инлайн вызовов существенно помогает в поиске ILP. Однако для успешных inline-подстановок требуется выполнение ряда условий.
Первое — вызываемая процедура должна находиться в том же самом модуле, где и вызвавшая ее процедура. Для решения этой проблемы предусмотрена возможность сборки проекта в режиме межмодульной оптимизации. Для этого на вход компилятору следует подать опцию
-fwhole.Второй проблемой является вызов по косвенности. Компилятор может бороться с косвенностью:
либо с помощью межмодульного анализа, определяющего множество функций, которые могут быть вызваны в каждой точке вызова по косвенности; этот анализ также доступен по опции
-fwhole;либо с помощью профилирования значений переменных. В этом случае необходимо использовать двухфазную компиляцию с профилированием значений указателей на процедуры, дополнительно к
-fprofile-generateдобавив опцию-fprofile-values. Информация о профилировании есть в блоке о двухфазной компиляции .
Для управления inline-подстановкой предусмотрены следующие опции:
ключевое слово inline;
атрибуты процедур:
__attribute__((noinline));
__attribute__((always_inline));
опции оптимизации
-O1,-O2,-O3;опция отключения
-fno-inline;опции тонкой настройки:
-finline-level=1.0– коэффициент k [0.1-20.0];-finline-scale=1.0– коэффициент увеличения основных ресурсных ограничений [0.1-5.0].
Рассмотрим пример, который на ВК «Эльбрус» будет выполняться быстрее, чем на ВК с архитектурой х86_64. Все примеры в этом методическом пособии будут проводиться в сравнении между следующими машинами:
ВК «Эльбрус 801-PC» с процессором «Эльбрус-8С» (8 ядер):
# uname -a
Linux blabla 4.19.0-0.1-e8c #1 SMP Fri Aug 16 19:53:19 GMT 2019 e2k E8C
MBE8C-PC v.2 GNU/Linux
# lcc -v
lcc:1.24.04:Jul-2-2019:e2k-v4-linux
Thread model: posix
gcc version 7.3.0 compatible.
# cat /etc/mcst_version
4.0-rc3
ВК с процессором Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz (8 ядер):
# uname -a
Linux debion 4.9.0-3.6-amd64 #1 SMP Tue Jun 4 14:10:20 GMT 2019 x86_64
Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz GenuineIntel GNU/Linux
# gcc -v
Используются внутренние спецификации.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/5.5.0/lto-wrapper
Целевая архитектура: x86_64-linux-gnu
Параметры конфигурации: ../configure --build=x86_64-linux-gnu --prefix=/usr
--libexecdir=/usr/lib --enable-shared --enable-threads=posix --disable-bootstrap
--enable-__cxa_atexit --enable-multilib --enable-clocale=gnu
--enable-languages=c,c++,fortran
Модель многопоточности: posix
gcc версия 5.5.0 (GCC)
# cat /etc/mcst_version
4.0-rc4
Пример:
#include <stdio.h>
#define REP 100000
#define N 10000
void f0(int *p)
{
*p = (*p) * (*p) + 1;
}
void f1(int *p)
{
*p = (*p) / ((*p) * (*p) + 1);
}
void f2(int *p)
{
*p = (*p)<<((*p) & 31);
}
void f3(int *p)
{
*p = (*p) + (*p)<<1 + (*p)<<7 + (*p)<<4;
}
void f4(int *p)
{
*p = (*p) ^ (int)( (*p) * 0.42 );
}
void f5(int *p)
{
*p = (*p) % 17;
}
int r[N];
#ifndef NOINLINE
#define NOINLINE __attribute__((noinline))
#endif
void NOINLINE sample(int i)
{
f0(&(r[i]));
f1(&(r[i+1]));
f2(&(r[i+2]));
f3(&(r[i+3]));
f4(&(r[i+4]));
f5(&(r[i+5]));
}
int main()
{
int i,k;
for (i=0; i<N; i++)
r[i]=i;
for (k=0; k<REP; k++)
{
for (i=0; i<(N-5); i+=6)
{
sample(i);
}
}
printf("%10i\n",r[0]);
return (int)r[0];
}
Компиляция под платформу «Эльбрус»:
/opt/mcst/bin/lcc -O3 ./t.c -o a.elb.noinline -fno-inline
/opt/mcst/bin/lcc -O3 ./t.c -o a.elb
/opt/mcst/bin/lcc -O3 ./t.c -o a.elb.aggr -DNOINLINE=
Эльбрус |
Intel |
Опции сборки |
|---|---|---|
real 5.15 |
real 1.83 |
|
user 5.14 |
user 1.83 |
|
sys 0.01 |
sys 0.00 |
|
real 18.37 |
real 2.73 |
|
user 18.36 |
user 2.73 |
|
sys 0.00 |
sys 0.00 |
|
real 0.71 |
real 1.70 |
|
user 0.71 |
user 1.70 |
|
sys 0.00 |
sys 0.00 |
Опция -fno-inline запрещает инлайн-подстановку, и в таком режиме программа на Эльбрусе
существенно уступает в производительности. Опция -DNOINLINE= специфична для приведенного примера,
она управляет возможностью подстановки функции sample() в тело цикла в функции main()
за счет выключения аттрибута __attribute__((noinline)).
В случае инлайна всех функций f() в sample() и sample() в main()
компилятор смог дополнительно воспользоваться параллельностью итераций цикла main().
Об этой технике подробно рассказывается в следующем разделе.
6.3. Программная конвейеризация¶
Под конвейеризацией принято понимать метод организации длительной циклической работы. В основе конвейеризации лежит разбиение одного цикла работы на несколько стадий, при котором каждая стадия принимает на вход результат предыдущей стадии и передает собственный результат следующей стадии; при этом для достижения желаемого эффекта время работы стадий должно быть существенно меньше исходного цикла.
В качестве примеров конвейеризированной работы можно привести:
тушение пожара методом передачи ведер по цепочке:
- исходный цикл:
принести полное ведро от реки до пожара и добежать от пожара до реки с пустым ведром;
- стадии:
работа отдельных людей в цепочке по передаче полного ведра от предыдущего к следующему человеку в направлении пожара, и пустого в обратном направлении;
автоматизированную сборку автомобиля:
- исходный цикл:
полная сборка автомобиля (~сутки);
- стадии:
работа отдельного комплекса роботов с полуготовым автомобилем на конвейерной ленте (~час).
В обоих случаях эффект заключается в увеличении темпа: растет количество принесенных ведер в минуту, количество собранных автомобилей в сутки.
Для циклов программы конвейеризация означает сокращение суммарного времени выполнения всех итераций цикла за счет большего темпа запуска итераций цикла в работу. Принцип работы конвейеризации цикла проиллюстрирован на рис. Пример работы конвейера.
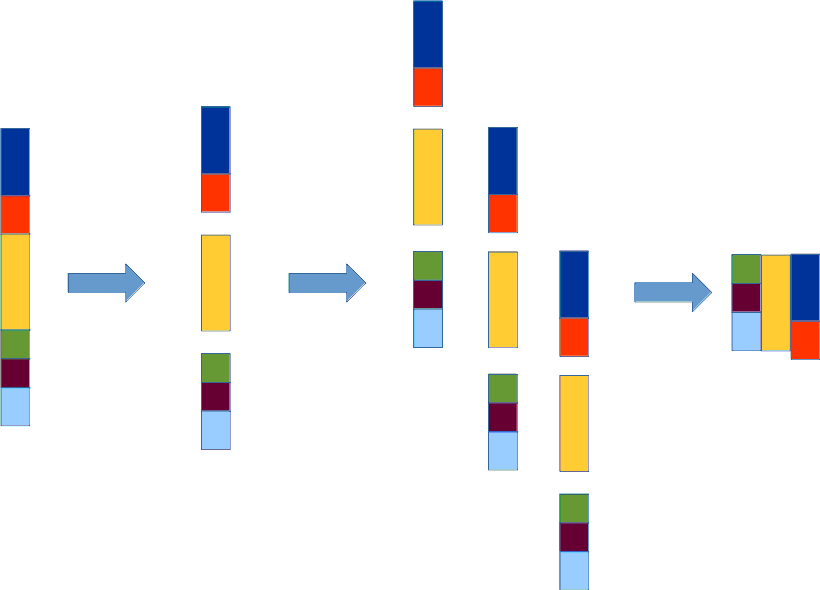
Пример работы конвейера¶
6.3.1. Важность конвейеризации для VLIW и OOOSS¶
VLIW:
Без конвейеризации все итерации цикла будут исполняться строго последовательно. Конвейеризация дает многократное ускорение циклов. Заметим, что эффект, схожий с конвейеризацией, предоставляет распространенная компиляторная оптимизация «раскрутка цикла» (loop unrolling). В этой оптимизации в одном «туловище» раскрученного цикла выполняется несколько рядом стоящих итераций.
OOOS:
Для ООOSS конвейеризация происходит за счёт аппаратного планирования. В OOOSS предсказатель переходов предсказывает переход по обратной дуге, и это позволяет начать исполнять операции со следующей итерации еще до конца текущей. Эффективность конвейеризации цикла в OOOSS ограничена объемами ROB (буфер переупорядочения) и количеством операций на одной итерации цикла.
6.3.2. Пример ручной конвейеризации цикла¶
Рассмотрим цикл со слабой зависимостью между итерациями:
do
{
s += 1.0/(a[i]*a[i] + 1.0);
}
while (i++ < N);
Ассемблер такого цикла будет следующим:
ldd [%r_a %r_i_], %r0 fmuld %r0, %r0, %r1 faddd %r1, 1.0, %r2 fdivd 1.0, %r2, %r3 faddd %r_s, %r3, %r_s addd %r_i, 1, %r_i addd %r_i_, 8, %r_i_ cmpl %r_i, %r_N, %pred0 ct %ctpr1 , %pred0
Операцию подготовки перехода
disp :loop_head, %cptr1
В данном случае вынесли в качеcтве инварианта и спланировали перед входом в цикл.
Для лучшей наглядности изменены названия регистров. Мнемоники команд сохранены. Действия описаны так, как если бы они выполнялись последовательно.
В примере использованы следующие операции:
ldd — чтение;
fmuld — умножение;
faddd — сложение;
fdivd — деление;
cmpl — сравнение;
ct — переход.
Из этих операций состоит цикл. Их можно выполнить в каком-то порядке, некоторые операции могут смещаться относительно других. Заметим, что большую часть операций с соседних итераций цикла можно исполнять независимо. Зависимыми от предыдущей итерации являются операции, помеченные красным цветом.
Каждая из этих операций вырабатывает результат, который используется этой же операцией на следующей итерации.
Цикл написан в предположении, что мы работаем с типом double. Чтобы не делать сдвига переменной i в качестве аргумента для чтения, мы увеличиваем i_ для продвижения по массиву (i_ определяет смещение).
Для большего понимания выпишем всю последовательность элементарных действий на одной итерации цикла:
читается a[i] по смещению
i_и кладется в%r0;%r0умножается на%r0и записывается в%r1;к
%r1прибавляется единица и происходит запись в%r2;единицу делим на
%r2и кладем результат в%r3;%r3прибавляем к S и кладем результат в регистр для S;производим инкремент i;
i_увеличиваем на 8;сравниваем i и N;
делаем переход в начало цикла.
В разделе Планирование кода уже упоминалось, что операции имеют различную длительность. Планирование этого цикла с учётом длительностей операций для процессора «Эльбрус-4С» выглядит следующим образом:
0 ldd [%r_a %r_i_], %r0
0 addd %r_i, 1, %r_i
0 addd %r_i_, 8, %r_i_
1 cmpl %r_i, %r_N, %pred0
2
3 fmuld %r0, %r0, %r1
4
5
6
7 faddd %r1, 1.0, %r2
8
9
10
11 fdivd 1.0, %r2, %r3
...
22 faddd %r_s, %r3, %r_s
22 ct :loop_head, %pred0
В данном примере подняты максимально вверх те операции, на которые другие операции не оказывают давления (не зависят по регистрам или данным).
Поднялись вверх операции i++ и i_+8.
От операции чтения a[i] до умножения fmuld три такта, это обусловлено длительностью операции чтения из L1 кэша.
Операция fmuld работает 4 такта, за него зацеплена операция сложения, которая будет работать в 7-м такте, так как ей требуется результат умножения.
Операция faddd также работает 4 такта, соответственно операция fdivd, зависящая от неё по %r2, будет выполняться в 11-м такте.
Операция деления является длительной операцией и выполняется 11 тактов (или более, в зависимости от используемой разрядности), поэтому операция сложения с S
будет производиться только в 22 такте и вместе с ней сможет выполниться операция перехода. Таким образом, одна итерация цикла требует 23 такта для выполнения.
Начнем процесс конвейеризации цикла с выполнения переноса операций с критического пути по обратной дуге.
Первой из таких операций является операция чтения в 0 такте, которая отодвигала умножение в третий такт.
Перенесем эту операцию по всем переходам в голову цикла - это переход по обратной дуге цикла, и вход в голову цикла извне.
После переноса по обратной дуге операция чтения поднимется и окажется в такте T=1.
Операция чтения не может подняться в нулевой такт, так как перед выполнением чтения должно произойти изменение i_.
После переноса чтения умножение может подняться в нулевой такт, так как теперь на него ничего не давит и все, что зависело от умножения, также поднимается вверх.
Но теперь умножение, пришедшее в нулевой такт, давит на сложение в 4-м такте. Также перенесем, как и ldd, операцию fmuld по обратной дуге.
0 addd %r_i, 1, %r_i
0 addd %r_i_, 8, %r_i_
0 fmuld %r0, %r0, %r1
1 cmpl %r_i, %r_N, %pred0
1 ldd .s [%r_a %r_i_], %r0
3
3
4 faddd %r1, 1.0, %r2
5
6
7
8 fdivd 1.0, %r2, %r3
9
10
11
...
19 faddd %r_s, %r3, %r_s
19 ct :loop_head, %pred0
После переноса операции fmuld зависящая от нее операция faddd поднимется в нулевой такт. Операция fmuld встанет в четвертом такте, так как она зависима от операции чтения в первом такте.
0 addd %r_i, 1, %r_i 0 addd %r_i_, 8, %r_i_ 0 faddd %r1, 1.0, %r2 1 cmpl %r_i, %r_N, %pred0 1 ldd [%r_a %r_i_], %r0 3 3 4 fdivd 1.0, %r2, %r3 4 fmuld %r0, %r0, %r1 6 7 8 9 10 11 ... 15 faddd %r_s, %r3, %r_s 15 ct :loop_head, %pred0
Таким образом, цикл сократился еще на 4 такта. Следующим шагом перенесем fadd из нулевого такта:
0 addd %r_i, 1, %r_i 0 addd %r_i_, 8, %r_i_ 0 fdivd 1.0, %r2, %r3 1 ldd [%r_a %r_i_], %r0 1 cmpl %r_i, %r_N, %pred0 2 3 fmuld %r0, %r0, %r1 3 4 5 6 7 faddd %r1, 1.0, %r2 8 9 10 11 faddd %r_s, %r3, %r_s 11 ct :loop_head, %pred0
Если теперь попытаться сделать следующий шаг и перенести через обратную дугу операцию деления, поднявшуюся в 0 такт, то мы столкнемся с проблемой т.н. антизависимости операций. Термин антизависимость, или зависимость типа Write-After-Read, обозначает невозможность переставить местами две операции, из которых:
первая читает значение из некоторого ранее определенного регистра;
вторая записывает в этот же регистр новое значение, после чего старое значение регистра пропадает.
В нашем примере проблема заключается в антизависимости faddd <- %r3 и fdivd -> %r3 со следующей итерации.
Для борьбы с антизависимостью используется техника переименования регистров: нижней операции нужно назначить другой регистр для записи результата (и запомнить этот факт для дальнейших операций, использующих результат нижней операции). В OOOSS переименование регистров производится аппаратно с помощью скрытого регистрового файла. Для архитектуры Эльбрус используется механизм явного переименования регистров - базированные регистры. Они описаны в разделе Пространство регистров подвижной базы. Программные соглашения использования базированных регистров.
Ассемблерная мнемоника базированных регистров — %b[].
Циклическое переименование (вращение окна) базированных регистров с помощью операции abn показано на рисунке
Циклическое переименование базированных регистров операцией abn.
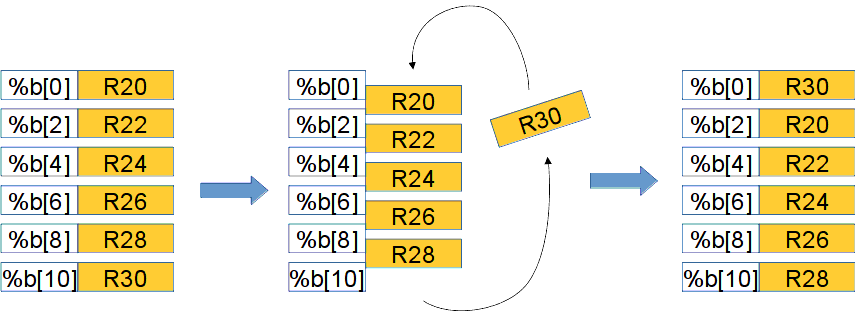
Циклическое переименование базированных регистров операцией abn¶
Теперь проблема антизависимости для длинных операций на соседних итерациях цикла может быть решена с помощью
операции вращения регистров abn, поставленной в последнем такте цикла вместе с операцией перехода по обратной дуге.
Механизм вращения позволяет длинной операции (в нашем случае операции деления fdiv) писать
в различные физические регистры, обращаясь к ним с помощью одной и той же мнемоники %b[X].
Это позволит продолжить перенос по обратной дуге с той лишь разницей, что регистр,
с которым будет работать длинная операция fdiv, будет заменен на базированный.
Приведем следующий шаг процесса переноса, сокращающий цикл до 8 тактов:
0 addd %r_i, 1, %r_i 0 faddd %r1, 1.0, %r2 1 addd %r_i_, 8, %r_i_ 1 ldd [%r_a %r_i_], %r0 1 cmpl %r_i, %r_N, %pred0 2 4 fmuld %r0, %r0, %r1 4 fdivd 1.0, %r2, %b[0] 5 6 7 faddd %r_s, %b[2], %r_s 7 abn 7 ct :loop_head, %pred0
Здесь произошло сразу несколько событий:
операции ldd и fmuld перенесены еще на одну итерацию вверх, они теперь помечены светло-зеленым;
ради операции ldd перенесена по обратной дуге операция addd, инкрементирующая регистр
%r_i_;операция fdivd перенесена по обратной дуге и помечена зеленым;
добавлена операция abn для циклического переименования регистров
%b[0]->%b[2];операции fdivd назначен базированный регистр
%b[0]. Для использования ее значения на следующей итерации операции faddd назначен регистр%b[2]- в нем окажется нужное значение после исполнения операции abn.
На данном этапе длинная цепочка вычислений на одной итерации цикла разбита уже на три стадии:
ldd -> fmuld ->-> faddd -> fdivd ->-> faddd
Если продолжить процесс, можно довести планирование до 4-х тактов.
0 addd %r_i, 1, %r_i 0 cmpl %r_i, %r_N, %pred0 1 addd %r_i_, 8, %r_i_ 2 fmuld %r0, %r0, %r1 2 faddd %r1, 1.0, %r2 2 fdivd 1.0, %r2, %b[0] 3 ldd [%r_a %r_i_], %r0 3 faddd %r_s, %b[6], %r_s 3 abn 3 ct :loop_head, %pred0
Обратим внимание, что fdivd пишет в регистр %b[0], а faddd потребляет регистр %b[6] -
такая дистанция образовалась из-за того, что между заброшенным по обратной дуге fdiv
и использующим его результат fadd успевает исполниться три операции abn.
Сделать так потребовалось для того, чтобы выдержать задержку в 11 тактов за несколько
итераций цикла длиной 4 такта.
6.3.3. Логическая и физическая итерации¶
Для конвейеризированных циклов приняты термины Логическая и Физическая итерация.
- Логическая итерация
последовательность операций одной итерации исходного цикла.
- Стадия
одна из n последовательных частей логической итерации, которая будет исполняться последовательно.
- Физическая итерация
набор совмещенных стадий различных соседних логических итераций, по составу операций совпадающий с логической итерацией, а по длине планирования - с самой длинной стадией.
- Пролог
разгон цикла, первые n-1 физических итераций цикла, предшествующих завершению исполнения первой логической итерации.
- Эпилог
торможение цикла, последние n-1 физических итераций цикла, завершающие последнюю логическую итерацию.
Для рассмотренного нами примера ручной конвейеризации длина логической итерации составляет 23 такта, длина физической итерации 4 такта, число стадий равно 6. Если у исходного цикла количество итераций было равно 100, то у конвейеризированного цикла оно составит 100 + (6-1) = 105, т.к. к ним добавится 5 итераций пролога.
Длина физической итерации ограничена снизу:
количеством ресурсов ШК (например, количеством АЛУ);
длиной рекуррентности;
длиной последней стадии, содержащей операции с побочным эффектом (например, записи или условные переопределения).
Для того, чтобы цикл смог стать конвейеризированным, необходимо выполнить ряд условий. Требуется:
отсутствие операций вызова в теле цикла;
наличие единственной обратной дуги и единственного выхода как альтернативы обратной дуге;
отсутствие ветвлений в теле цикла.
Также можно выделить аспекты, которые делают конвейеризированный цикл малоэффективным:
число итераций меньше либо сравнимо по величине с числом стадий;
длина рекуррентности сравнима с длиной исходной итерации.
6.3.4. Примеры рекуррентности¶
i++;
0 addd %r_i, 1, %r_i
Рекуррентность ограничивает длину стадии снизу. В случае i++ длина рекурентности составляет 1 такт в соответствии с длительностью операции.
Операция читает из регистра r_i и пишет в регистр r_i.
s += sqrt(t);
0 fsqrts %r_t, %r0 15 fadds %r_s, %r0, %r_s
В этом примере, выполняющемся 16 тактов, длинная операция sqrt не участвует в рекуррентности, которая состоит из единственной операции fadds.
a[i] = a[j] + 4;
0 ldd [%r_a_m16 %r_j_], %r0 3 addd %r0, 4, %r1 4 std %r1, [%r_a %r_i_]
В этом примере показана рекуррентность между чтением и записью, так как нет уверенности, пересекаются ли области памяти:
та, из которой мы читаем со смещением j;
та, в которую пишем со смещением i.
В распоряжении программиста есть аппаратно-программные приемы, чтобы избавиться от рекуррентности. Рекуррентность через единственную ассоциативную операцию может быть уменьшена за счет:
раскрутки цикла:
s += (sqrt(t0) + sqrt(t1));
0 fsqrts %r_t0, %r0 2 fsqrts %r_t1, %r1 17 fadds %r0, %r1, %r2 21 fadds %r_s, %r2, %r_s
-fassociated-math или более общую опцию -ffast-math.редукции с помощью вращаемых регистров:
s1 = s0 + sqrt(t);
s0 = s1;
…
// после цикла
…
s = s0 + s1;
0 fsqrts %r_t, %r0 15 fadds %b[4], %r0, %b[0] … // после цикла … fadds %b[2], %b[0], %r_s
Принцип тот же, но вместо раскрутки используется базированный регистр, заменяющий одно суммируемое значение
на два, расположенных в соседних регистрах, в одном из которых соберется сумма sqrt(t)
с операций с четным номером, а в другом - с нечетным.
После цикла эти регистры необходимо сложить для получения полной суммы.
Это также существенно меняет порядок вещественных операций и требует опции
-ffast-math или -fassociative-math.
Отдельно нужно отметить, что операции, которые не могут исполняться спекулятивно, должны размещаться на последней стадии цикла. К таким операциям относятся, например, операции записи в память. Если при этом на итерации цикла есть операции чтения, которые зависят от операции записи, то они тоже вынуждены размещаться на последней стадии. Пример:
a[rnd]++;
s+=a[i];
0 ldw [%r_a %r_rnd_], %r0 3 adds %r0, 1, %r1 4 stw %r1, [%r_a %r_rnd_] 5 ldw [%r_a %r_i_], %r2 8 adds %r_s, %r2, %r2
Это показывает важность разрыва зависимости по памяти между операциями чтения и записи в конвейеризируемых циклах. Для этого можно пользоваться различными приемами, они описаны в последуюших разделах.
6.3.5. Управление конвейеризацией¶
Для управления конвейеризацией предусмотрены следующие опции и прагмы:
#pragma loop count(N)
подсказка компилятору о среднем количестве итераций цикла. Позволяет компилятору принять положительное решение о конвейеризации в тех случаях, когда предсказанное самим компилятором количество итераций цикла было небольшим. Эту же посдказку можно использовать для того, чтобы отключить конвейеризацию с негативным эффектом для циклов с малым количеством итераций.
#pragma ivdep
разрыв зависимостей между операциями чтения и записи, расположенными на разных итерациях цикла; позволяет уменьшить длину последней стадии и увеличить эффективность конвейеризации.
-fswp-maxopers=N
максимальное количество операций для цикла, чтобы его можно было рассматривать для конвейера. Конвейеризация полностью отключается при значении
swp-maxopers = 0. Для значений порядка 1000 нужно бояться сильного роста времени компиляции проекта. Значение по умолчанию - 300.
-fforce-swp
отключает оценки качества конвейеризации в пользу безусловного применения. Использовать можно для экспериментов.
6.3.6. Пример c конвейеризацией цикла¶
#include <stdio.h>
#define REP 100000
#define N 30000
double const c1=1.0, c2=0.01, c3=0.99, c4=0.01, c5=1.01, c6=0.01, c7=0.98, c8=-0.01;
double a[N];
void sample(double *d)
{
int i;
for (i=0; i<N; i+=4)
{
d[i]=(((d[i]*c1+c2)*c3+c4)*c5+c6)*c7+c8;
}
}
int main()
{
int i,k;
for (i=0; i<N; i++)
{
a[i]=i/N;
}
for (k=0; k<REP; k++)
{
sample(a);
}
printf("%10.7f\n",a[N-4]);
return a[N-4];
}
Компиляция под платформу «Эльбрус»:
/opt/mcst/bin/lcc -O3 ./t.c -o a.O3 -fno-inline
/opt/mcst/bin/lcc -O3 -ffast ./t.c -o a.O3f -fno-inline
/opt/mcst/bin/lcc -O3 -fswp-maxopers=0 -ffast ./t.c -o a.O3noswp -fno-inline
Компиляция под платформу Intel:
gcc ./t.c -O3 -fno-inline
Эльбрус |
Intel |
Опции сборки |
|---|---|---|
0.9700975 |
0.9700975 |
|
real 1.05 |
real 1.32 |
|
user 1.05 |
user 1.32 |
|
sys 0.00 |
sys 0.00 |
|
0.9700975 |
Опция |
|
real 0.69 |
||
user 0.69 |
||
sys 0.00 |
||
0.9700975 |
Опция не поддерживается |
|
real 4.12 |
||
user 4.11 |
||
sys 0.00 |
Первым полем перед временами исполнения в таблице приведено значение результата программы.
При этом на последних версиях компилятора lcc-1.24 даже с опцией -fswp-maxopers=0 сработает аппаратная подкачка массива с помощью apb.
В результате может получиться очень быстрое вычисление, сбивающее с толку, так как результат ожидался более медленный.
/opt/mcst/bin/lcc -O3 -fswp-maxopers=0 -ffast ./t.c -o a.O3noswp -fno-inline
hostname /export/minis/01_swp # time -p ./a.O3noswp
0.9700975
real 0.58
user 0.58
sys 0.00
6.4. Слияние альтернатив условий¶
Рассмотрим простейшую условную конструкцию:
int f(int с, int *p)
{
int r=0;
if (c>0)
r += *p;
return r;
}
При компиляции с выключенной оптимизацией мы увидим следующий код:
f:
{
setwd wsz = 0x4, nfx = 0x1
}
{
nop 4
adds,0,sm 0x0, 0x0, %r4
cmplesb,1 %r0, 0x0, %pred0
disp %ctpr1, .L5; ipd 2
}
{
ct %ctpr1 ? %pred0
}
.L8:
{
nop 2
ldw,0 %r1, 0x0, %r5
}
{
adds,0 %r4, %r5, %r4
}
.L5:
{
nop 5
sxt,0,sm 0x2, %r4, %r0
return %ctpr3; ipd 2
}
{
ct %ctpr3
}
Видим, что код получился очень рыхлым - на 6 операций приходится 14 тактов, если условие не выполняется, и 18 тактов, если условие выполняется. Во всех трех участках кода, разделенных метками, количество тактов определяют операции подготовки перехода disp и return.
Архитектура Эльбрус предоставляет возможность сделать этот код более компактным за счет замены операций условного перехода на предикатный (условный) режим исполнения отдельных операций.
f:
{
setwd wsz = 0x4, nfx = 0x1
return %ctpr3; ipd 2
adds,0 0x0, 0x0, %g16
}
{
nop 1
cmplesb,0 %r0, 0x0, %pred0
}
{
nop 3
ldw,0 %r1, 0x0, %g16 ? ~%pred0
}
{
ct %ctpr3
sxt,3 0x2, %g16, %r0
}
Рассмотрим, как работает приведенный код. Видим, что меток в коде не осталось, есть только одна операция подготовки
возврата из процедуры и одна операция возврата. Операция сравнения cmplesb все так же записывает результат
в предикатный регистр %pred0, но теперь он используется не для перехода, а для управления исполнением операции ldw.
Это задается с помощью мнемоники:
oper arg1, arg2, res ? pred
Если значение предикатного регистра равно 0, операция не будет выполнена. Можно задать управление с помощью инвертированного предиката:
oper arg1, arg2, res ? ~pred
В этом случае операция не будет выполнена при значении предикатного регистра 1.
Таким образом, в регистр %g16 есть две записи:
безусловная запись значения 0 операцией adds;
условная запись прочитанного из памяти значения *p операцией ldw.
Время спланированного исполнения такого кода составляет 8 тактов, что заметно лучше исходного времени 14-18 тактов.
Показанный прием называется слиянием альтернатив условного кода, или предикацией. Далее будем называть его «слиянием кода». Его можно применять не только к элементарным условным конструкциям, но и к более сложным. При этом условия, управляющие исполнением отдельных операций, будут вычисляться посредством разных операций сравнения. Для этого в архитектуре Эльбрус предусмотрены логические операции над предикатными регистрами.
Доступны следующие операции над предикатами:
пересылка предиката в локальный предикат и обратно;
pass %pred0, @p0
pass @p1, %pred2
логическая функция & с возможностью инверсии аргументов;
andp @p2, ~@p3, @p4
пересылка предиката под условием;
movp @p2, ~@p3, @p4
В одной ШК могут выполниться одновременно до трех логических операций andp/movp, при этом две из них могут быть зацеплены зависимостью следующим образом:
%pred3 = %pred0 & ~%pred1
%pred4 = %pred3 & %pred 2
В ассемблере предикатные операции выглядят так:
pass %pred0, @p0
pass %pred1, @p1
pass %pred2, @p2
andp @p0, ~@p1, @p3
pass @p3, %pred3
andp @p3, @p2, @p4
pass @p4, %pred4
6.4.1. Важность слияния кода для VLIW и OOOSS¶
VLIW:
среднее количество операций на линейном участке слишком мало для выявления ILP;
перемешивание операций с соседних участков позволяет повысить ILP;
объединение линейных участков позволяет уменьшить долю дорогостоящих операций перехода.
OOOSS:
ввиду наличия аппаратного предсказания траекторий исполнения кода слияние требуется в редких, плохо обнаруживаемых случаях непредсказуемых ветвлений;
поддержка условных операций в системе команд довольно слабая, зачастую реализованы только условные пересылки.
6.4.2. If-Conversion¶
If-Conversion — это слияние нескольких линейных участков, связанных друг с другом в подграф графа потока управления, в один участок кода, с использованием предикатного режима исполнения отдельных операций. Цель слияния - увеличение контекста поиска и выражения параллелизма уровня операций, а также удаление операций перехода.
Рассмотрим немного более сложный пример:
#define UL unsigned long
void adds(UL as, UL am, UL bs, UL bm, UL *ress, UL *resm, UL s)
{
if (as == bs) {
*resm = am + bm;
*ress = as;
}
else if (am >= bm) {
*ress = as;
if (!s)
(*resm)++;
}
else {
*ress = bs;
if (!s)
(*resm)--;
}
}
На рисунке ниже изображен граф потока управления, соответствуюший этой процедуре. Под таким графом традиционно понимается граф, узлами которого являются линейные участки кода, завершающиеся единственной операцией передачи управления (перехода), а дугами соединяются линейные участки, между которыми возможны переходы. При этом переход может выполняться в одно, два или множество мест (см. рис. Граф потока управления и траектории исполнения кода).
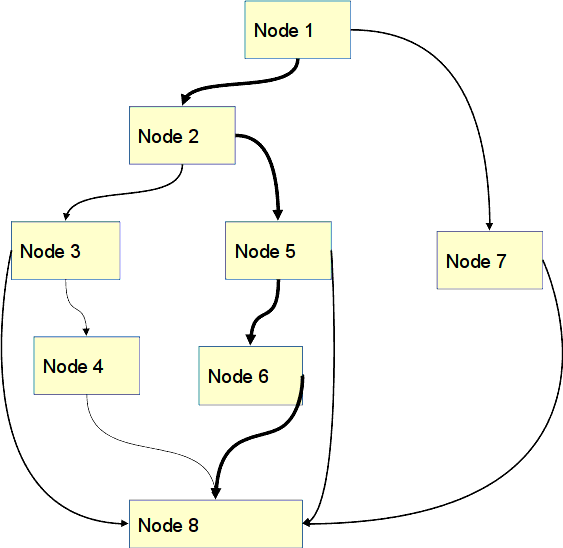
Граф потока управления и траектории исполнения кода¶
Теперь рассмотрим ассемблерное содержимое линейных участков (см. рис. Разветвленный код).
Узлы представлены номерами N1,.. N8.
Каждому узлу в соответствие приведено количество тактов, за которое он выполняется.
Внутри каждого узла представлен набор ассемблерных операций, реализующих данный узел.
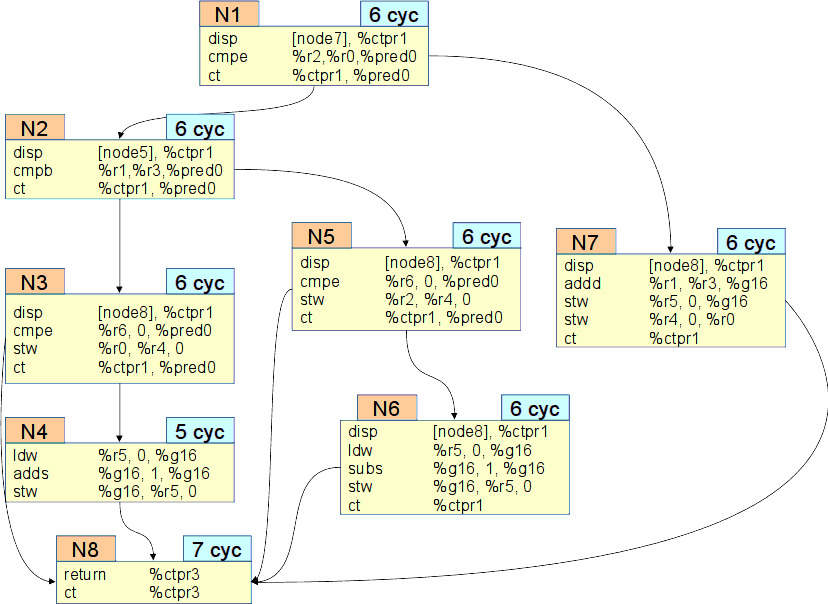
Разветвленный код¶
Рассмотрим маленький участок этого графа между первым и вторым узлом.
Из первого узла есть два выхода в узел N2 и в узел N7.
Из второго также есть два выхода в узлы N3 и N5. Суммарное время выполнения узлов - 12 тактов.
В обоих узлах используется операция подготовки перехода disp, операция сравнения cmp и операция перехода ct.
Перенесем операцию cmpb из узла 2 вверх в узел 1. На рис. Перенос операций показано, что в таком случае произойдёт с узлами.
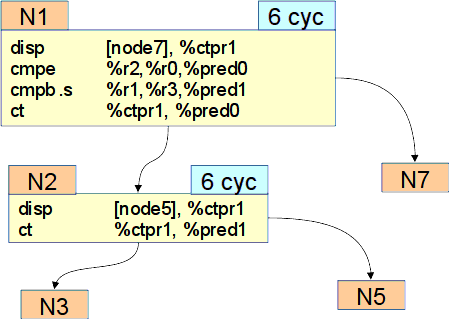
Перенос операций¶
В узле 2 остались операции подготовки и перехода, и на данном этапе планирование не уменьшилось. Эти операции также можно перенести в узел 1, тем самым превратив его в //гиперузел// и изменив планирование. В гиперузле получим три выхода — два перехода и один провал (см. рис. Гиперузел).
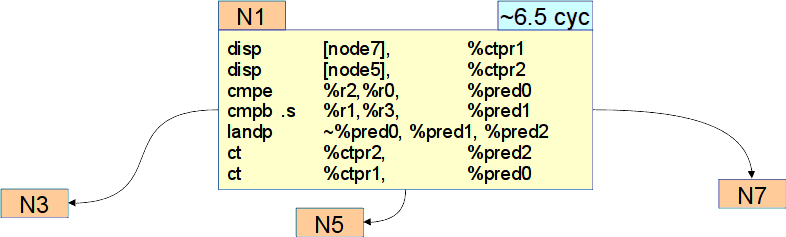
Гиперузел¶
Имеем две операции подготовки, две операции сравнения, две операции перехода и новую операцию landp -
логическую операцию И над двумя предикатными регистрами.
Она необходима для определения сложного условия перехода в узел N5,.
Время выполнения гиперузла станет порядка 6,5 тактов: иногда мы будем выходить через 6 тактов в узел N7,
а иногда через 7 тактов в узлы N3 и N5.
6.4.3. Спекулятивный режим¶
Для повышения параллелизма на уровне операций часто бывает полезно начать выполнять операцию до того, как станет известно, нужно ли было выполнять эту операцию. В случае, если операция может привести к прерыванию (например, чтение из памяти по недопустимому адресу, или деление на 0), такое преждевременное исполнение может привести к некорректному аварийному выходу из программы. Для того, чтобы решить эту проблему, в архитектуре «Эльбрус» допускается выполнение операций в режиме отложенного прерывания, также называемом спекулятивным режимом исполнения операции. Для хранения информации об отложенном прерывании ячейки памяти, числовые и предикатные регистры снабжены дополнительным битом (тэгом), по одному биту на одно слово (1 слово = 4 байта = 32 бита) в памяти, по два на 64-битный числовой регистр (по одному на старшую и младшую части), и по одному на каждый предикатный регистр. 1 в бите тэга означает, что значение регистра указывает на отложенное прерывание (диагностическое значение).
Примерная схема работы такова:
вместо выработки прерывания операция, имеющая спекулятивный признак (везде далее «спекулятивная операция»), записывает 1 в диагностический бит результата;
диагностический операнд у спекулятивной операции приводит к выработке в ней диагностического результата;
диагностический операнд у неспекулятивной операции приводит к выработке отложенного прерывания.
Возможности оптимизации, предоставляемые спекулятивным режимом исполнения, таковы: в спекулятивном режиме операция может быть исполнена раньше, чем условный переход на линейный участок, содержащий эту операцию, и логика исполнения программы при этом сохраняется.
Пример:
int* a;
…
if (a!=NULL)
{
*a++;
}
…
Такой код может быть выполнен при помощи следующих операций:
0 disp label => ctpr1 ! подготовка обходной метки
0 cmpe Ra, 0 => p0 ! сравнение указателя на равенство 0
4 ct ctpr1 ? p0 ! условный переход на обходную метку
5 ld Ra, 0 => Rx ! чтение из указателя a
8 add Rx, 1 => Ry ! инкремент результата чтения
9 st Ra, 0 <= Ry ! запись в a результата инкремента
label:
время работы — 10 тактов.
Спекулятивный режим позволяет спланировать код с большей параллельностью:
0 disp label => ctpr1 ! подготовка обходной метки
0 cmpe Ra, 0 => p0 ! сравнение на равенство
0 ld.s Ra, 0 => Rx ! чтение из указателя a
3 add.s Rx, 1 => Ry ! инкремент результата чтения
4 ct ctpr1 ? p0 ! условный переход на обходную метку
5 st Ra, 0 <= Ry ! запись в a результата инкремента
label:
время работы — 6 тактов.
Обратим внимание, что операции ld и add, поставленные в спекулятивный режим, будут исполнены независимо от результата сравнения,
причем при a==NULL результат чтения будет диагностическим (чтение по адресу NULL вызывает прерывание, которое будет отложено).
При этом результат операции add, содержащий диагностическое значение, не будет использован, т.к. операция st исполнится только при a!=NULL.
Скомбинировав предикатный и спекулятивный режимы, можно получить еще более быстрый код:
0 ld.s Ra, 0 => Rx ! чтение из указателя a
0 cmpe Ra, 0 => p0 ! сравнение на равенство
3 add.s Rx, 1 => Ry ! инкремент результата чтения
4 st Ra, 0 <= Ry ? ~p0 ! запись под предикатом не-p0
время работы — 5 тактов.
Отметим, что приведенный код является более параллельным, чем в чистом предикатном режиме, поскольку цепочка операций ld.s и add.s не зацеплена за операцию сравнения, вырабатывающую предикат.
Также отметим, что некоторые операции нельзя исполнять в спекулятивном режиме, такие как передача управления или запись в память.
6.4.4. Итог слияния примера со сложным условным кодом¶
Используя спекулятивный и предикатный режим, показанный в начале этого раздела, граф потока управления в виде ассемблерных операций можно слить в один гиперузел с временем выполнения 7 тактов. Такой узел выглядел бы следующим образом:
return %ctpr3
ldw .s [%r5 + 0x0], %g16
adds .s %r1, %r3, %g18
cmpe .s %r6, 0x0, %pred0
cmpb .s %r1, %r3, %pred1
cmpe %r0, %r2, %pred2
landp ~%pred2, ~%pred1, %pred3
landp %pred3, %pred0, %pred4
landp ~%pred2, %pred1, %pred5
landp %pred5, %pred0, %pred6
subs .s %g16, 0x1, %g17
adds .s %g16, 0x1, %g16
stw %r0, [%r4 + 0x0] ? %pred2
stw %g18 [%r5 + 0x0] ? %pred2
stw %r0, [%r4 + 0x0] ? %pred3
stw %r2, [%r4 + 0x0] ? %pred4
stw %g16, [%r5 + 0x0] ? %pred5
stw %g17, [%r5 + 0x0] ? %pred6
ct %ctpr3
6.4.5. Управление слиянием кода¶
При слиянии кода часть одного узла сливается с другим. Однако другие узлы могут иметь свои дуги на данный слитый узел. Ввиду этого происходит дублирование кода.
Влияние опций и других факторов на работу слияния:
6.4.6. Пример на слияние кода¶
#include <stdio.h>
#include <stdlib.h>
#define REP 100000
#define N 10000
int rn[N+63];
int a,b,c;
void sample(int ind)
{
int S;
S = rn[ind];
if ((S&1)&&(S<(1<<30)))
a++;
if (((S>>3)&1)&&(S<(1<<29)))
b++;
if (((S>>5)&1)&&(S<(1<<28)))
c++;
}
int main()
{
int i,k,S;
for (i=0; i<N; i++)
rn[i]=rand();
for (k=0; k<REP; k++)
for (i=0; i<N; i++)
{
sample(i+(k&63));
}
printf("%d %d %d\n",a,b,c);
return 0;
}
Компиляция под платформу «Эльбрус»:
/opt/mcst/bin/lcc -O3 ./t.c -o a.O3 -fno-inline
/opt/mcst/bin/lcc -O1 ./t.c -o a.O1 -fno-inline
Компиляция под платформу Intel:
gcc ./t.c -O3 -fno-inline
Эльбрус |
Intel |
Опции сборки |
|---|---|---|
244176687 123914132 |
|
|
63020334 |
||
real 42.64 |
||
user 42.62 |
||
sys 0.00 |
||
244176687 123914132 |
244176687 123914132 |
|
63020334 |
63020334 |
|
real 19.21 |
real 14.30 |
|
user 19.19 |
user 14.30 |
|
sys 0.01 |
sys 0.00 |
Для наглядности рекомендуется на платформе «Эльбрус» получить ассемблерный код и увидеть разницу между функцией sample с оптимизацией -O1 и -O3.
Будет заметна разница в наполненности ШК, а также в большом количестве дорогостоящих операций disp в неоптимизированном варианте.
6.4.7. Последствия явного спекулятивного режима¶
Некоторые последстивя спекулятивного режима ыли ранее представлены в книге в разделе SIGILL как сигнал о ошиках (см. SIGILL как сигнал об ошибках)
Рассмотрим последствия использования явного спекулятивного режима на примере:
#include <stdio.h>
#include <fenv.h>
#include <math.h>
double zero = 0;
double
own_sin (double x)
{
fenv_t env;
feholdexcept (&env);
return sin(x);
}
double
own_fma (double x, double y, double z)
{
if (!__builtin_isfinite (x) || !__builtin_isfinite (y))
return x * y + z;
else if (!__builtin_isfinite (z))
return (z + x) + y;
if (((x == 0 || y == 0) && z == 0))
{
x = ({ __typeof (x) __x = (x); __asm ("" : "+m" (__x)); __x; });
return x * y + z;
}
fenv_t env;
feholdexcept (&env);
long double x1 = (long double) x * ((1ULL << (64 + 1) / 2) + 1);
long double y1 = (long double) y * ((1ULL << (64 + 1) / 2) + 1);
long double m1 = (long double) x * y;
x1 = (x - x1) + x1;
y1 = (y - y1) + y1;
long double x2 = x - x1;
long double y2 = y - y1;
long double m2 = (((x1 * y1 - m1) + x1 * y2) + x2 * y1) + x2 * y2;
long double a1 = z + m1;
long double t1 = a1 - z;
long double t2 = a1 - t1;
t1 = m1 - t1;
t2 = z - t2;
long double a2 = t1 + t2;
a2 = a2 + m2;
a1 = a1 + a2;
return a1;
}
int main ()
{
double res = own_fma(1.23, 7.8, 9)/zero;
// double res = own_sin(0.5);
printf ("\nres=%e sticky=%x", res, fetestexcept(FE_ALL_EXCEPT));
return 0;
}
own_sin() - это вызов синуса с обнуленными ексепшенами или sticky битам.
own_fma() - это часть глбсишного fma. Там много лишнего, но это не позволяет компилятору все это свернуть и подставить готовый результат. Функция также очищает sticky вырабатывает inexact (или precision) exception. Деление на 0 после вызова own_fma() дает еще divide by zero exception.
В варианте запуска own_fma():
на x86:
gcc ~/t.c -lm -static; ./a.out
res=inf sticky=24
на e2k:
gcc ~/t.c -lm -static -O3; ./a.out
Illegal instruction
C запретом спекулятивных плавающих операций:
gcc -O3 t.c -static -lm -fno-spec-fp ; ./a.out
res=inf sticky=24
Вариант с запуском own_sin (надо откомментировать вызов own_sin и закомментировать вызов own_fma):
на x86:
gcc ~/t.c -lm -static; ./a.out
res=4.794255e-01 sticky=20
на e2k:
gcc -O3 t.c -static -lm -fno-spec-fp ; ./a.out
Illegal instruction
Тут и опция отказа от спекулятивных операций не спасает, поскольку падение происходит в библиотечном синусе.
Существующие проблемы:
в режиме закрытых масок и нулевыми sticky-битами спекулятивная операция, налетевшая на fp-исключение, выработает диагностику; из-за этого будет падение из-за замаскированного fp-искючения, которое формально будет выглядеть как sigill
в режиме открытых масок спекулятивная операция выдаст диагностику, на операции, использующей ее результат будет пойман sigill. Поэтому не стоит, рассчитывать на fp-исключения, так как написанный перехватчик для них, не сможет поймать и обработать этот sigill
Одним из решений может быть использование опции -fno-fp-spec для запрета спекулятивности fp-операций
Другое решение это сборка в этом режиме некоторых библиотечных функций, в частности, тех, которые управляют fp-исключениями
6.5. Конфликты операций работы с памятью. Анализ указателей. Разрыв зависимостей¶
6.5.1. Виды зависимостей между операциями¶
Операции внутри некоторого участка кода могут быть связаны зависимостями. Чем меньше зависимость между операциями, тем большего параллелизма можно достигнуть.
Существует 4 типа зависимостей между операциями (см. рис. Виды зависимостей между операциями):
- Flow
истинная зависимость, отражает поток данных. Одна операция пишет в регистр, следующая читает. Операция умножения пишет в
%r1, операция сложения читает из%r1.- Output
редкая зависимость, её пример: два раза производится запись в один и тот же регистр
%r1под разными условиями. Разрешается несовместными предикатами - теми, которые в логическом выражении оба не равны единице, т.е. их произведение равно нулю.- Anti
зависимость решается с помощью переименования регистров. На рис. Виды зависимостей между операциями регистр
%r0надо успеть прочесть в операции faddd, так как впоследствии в этот регистр будет помещено новое значение операцией fsubd.- Memory
конфликт доступа в память. Разноплановая зависимость, требует множества подходов. В примере на рис. Виды зависимостей между операциями есть операция записи и чтения, каждая работает со своим адресом. Зачастую на этапе компиляции про такие операции нельзя сказать, конфликтуют они или нет.
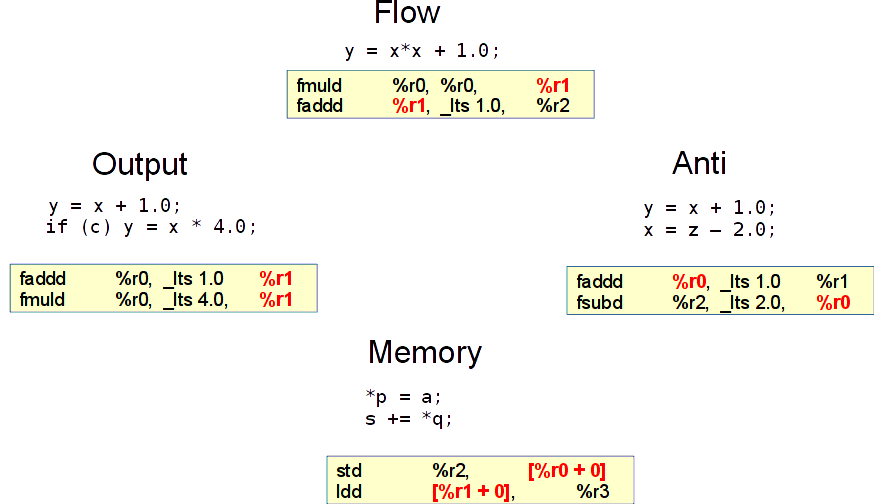
Виды зависимостей между операциями¶
Типичный связанный фрагмент потока данных выглядит таким образом, что первично выполняются операции чтения из памяти параметров или результатов вызовов, после этого происходят некоторые арифметические операции, завершающиеся записью в память, переходом или возвратом. На практике не возникает необходимость поднимать операции записи над чтением. Последняя стадия конвейера, как правило, включает в себя запись. Если мы поднимем чтение над записью, то это чтение также останется на последней стадии конвейера. Это нежелательный результат.
6.5.2. Зависимости по памяти¶
Можно выделить 4 типа зависимости по памяти:
Зависимость отсутствует, чтения не влияют друг на друга.
…
ldd [%r0 + 0], %r2
ldd [%r1 + 0], %r3
…
Разрыв позволяет переставлять записи, но это лишь немного улучшает параллельность операций.
… std %r2, [%r0 + 0] std %r3, [%r1 + 0] …
Бессмысленная. Необходимость поднимать записи выше чтений на практике не возникает.
… ldd [%r1 + 0], %r3 std %r2, [%r0 + 0] …
Самая важная. Разрыв зависимости позволяет потенциально совместить большие связанные группы операций.
… std %r2, [%r0 + 0] ldd [%r1 + 0], %r3 …
6.5.3. Важность разрешения зависимостей по памяти¶
VLIW:
операции с потенциальной зависимостью уменьшают ILP;
наличие memory-зависимостей часто снижает эффективность конвейеризации циклов;
некоторые оптимизации, в том числе универсальные, не могут применяться из-за memory-зависимостей.
OOOSS:
в момент исполнения операций становятся известны значения адресов, это позволяет устанавливать зависимость операций точно, а не потенциально;
некоторые универсальные оптимизации не могут применяться из-за memory-зависимостей.
6.5.4. Способы разрыва зависимостей по памяти¶
Выделяют два глобальных типа разрыва зависимостей по памяти:
Compile-time:
анализ указателей в пределах процедуры;
межпроцедурный анализ указателей;
анализ на основе типов данных;
на основании подсказок, опций, атрибутов.
Run-time:
скалярный разрыв, основанный на сравнении адресов;
цикловой разрыв, основанный на сравнении адресов;
разрыв с использованием аппаратной поддержки.
6.5.4.1. Статический анализ конфликтов по памяти¶
Анализ указателей в пределах процедуры определяет источник записи адреса в каждый указатель. Варианты, откуда он может прийти:
локальная переменная;
глобальная переменная;
адрес памяти, выделенной аллокатором;
значение адреса, пришедшее из параметра.
Выделенная аллокатором память для разных malloc внутри одной процедуры является гарантированно независимой. Также память, выделенная аллокатором, не конфликтует с памятью для локалов и глобалов. Поэтому для таких выделений памяти в рамках одной процедуры операции ldd можно будет спокойно поднять над std. Но если мы анализируем чтение из указателя, полученного в качестве параметра, про который мы не можем сказать, откуда он выделен, мы не можем поднять чтение над записью.
Межпроцедурный анализ является расширением статического. В нем производится анализ мест, откуда пришел указатель между процедурами — производится межпроцедурная пропагация списков локаций. Точки вызова процедур рассматриваются как присваивания фактических параметров в формальные.
Рассмотрим пример:
...
char *p0, *p1;
p0=&local_var;
p1=malloc(sz);
f(p0,p1);
...
void f(char* param_p0, char* param_p1)
{
(*param_p0)++;
(*param_p1)++;
return;
}
В этом примере без межпроцедурного анализа в функции f нельзя сказать, перестановочны ли чтения с записями.
Проведя межпроцедурный анализ, станет ясно, что в *param_p0 содержится адрес из локалов, а в *param_p1 - из кучи.
Тем самым будет обеспечена возможность перестановки чтения и записи.
Существующая проблема межпроцедурного анализа - в точках вызова по косвенности происходит массовая склейка формальных параметров различных процедур, анализ, соответственно, слабеет.
Еще одним вариантом разрыва memory-конфликтов является спецификатор __restrict.
Пример его применения можно увидеть в объявлении функции memcpy() в файле string.h.
Спецификатор __restrict для указателя «p» говорит, что к памяти, на которую указывает «p»,
можно обращаться только через этот указатель, разыменовывая его.
Т.е. «p» будет указывать на уникальную память. Для компилятора это важная информация, которая означает,
что операции чтения/записи с адресом, формируемым из __restrict переменной,
зависимы только с другими обращениями по этой переменной.
Ответственность за независимость адресов в случае использования __restrict перекладывается с компилятора на программиста.
В примере ниже операцию чтения из *bp можно поднять над записью ввиду того, что указатель *rp объявлен со спецификатором __restrict.
{
double * __restrict rp = param0;
Double * bp = param1;
...
*rp = a/(a*a+1);
b = *bp;
...
}
Следующим вариантом разрыва memory-конфликтов является использование «strict aliasing rule».
strict aliasing rule запрещает обращаться к одной памяти с помощью указателей несовместимых типов:
Для компилятора это означает, что операции чтения/записи несовместимых типов независимы.
В примере ниже операцию чтения из *ip можно поднять над операцией записи в *dp ввиду того, что *dp имеет тип double, а *ip имеет тип int:
{
double * dp = param0;
int * ip = param1;
...
*dp = sqrt(a);
b = *ip;
...
}
Для использования strict aliasing rule необходимо скомпилировать ваш проект с опцией -fstrict-aliasing или с опцией -ffast.
6.5.4.2. Динамический разрыв конфликтов по памяти¶
Рассмотрим run-time разрыв зависимостей или динамический разрыв зависимостей, при котором компилятор строит дополнительный код, чтобы в динамике разрешать конфликты по памяти, подобно OOOSS.
Первый метод динамического разрыва основан на сравнении адресов. Он применим только для выровненных указателей одинакового размера.
Для использования возможности такого динамического разрыва проект или файл должен быть скомпилирован с использованием опции -faligned.
Рассмотрим пример:
{
int * p0 = param0;
int * p1 = param1;
...
*p0 = a;
b = *p1;
...
}
В примере неизвестно, пересекаются ли адреса для указателей p0 и p1. Поэтому операцию чтения из p1 нельзя выполнить раньше записи в p0.
Однако, если собрать проект с опцией -faligned, компилятор сможет построить дополнительный код.
В языке Си такой код представлял бы из себя преждевременное чтение из p1 в некоторую переменную _b0,
после происходила запись «a» в *p0 с последующим использованием тернарного оператора, который бы проверял равенство адресов p1 и p0
и в зависимости от результата записывал бы в b либо значение «а», либо значение «_b0».
Пример:
{
...
_b0 = *p1;
*p0 = a;
b = (p1 == p0)? a : _b0;
...
}
На языке ассемблерного кода для платформы «Эльбрус» этот пример выглядел бы так:
...
ldw [%r1 + 0], %r4
cmpe %r1, %r0, %pred0
stw %r2, [%r0 + 0]
merges %r4, %r2, %pred0, %r3
...
В зависимости от времени выполнения ldw мы можем выиграть 1-2 такта.
Подобным методом разыва зависимостей в динамике является сравнение адресов — RTMD. Оптимизация RTMD применима для циклов с базовой индуктивностью и линейно изменяющимися адресами конфликтующих переменных.
Рассмотрим простой цикл с двумя конфликтующими адресами:
{
int * p0 = param0;
int * p1 = param1;
for (i=0; i<N; i++)
p0[i] = p1[i] + 1;
}
Компилятор может построить дополнительный код, превратив этот цикл в два цикла под разными условиями.
Первый цикл будет закладываться на то, что p0 и p1 не конфликтуют.
Второй же, напротив, будет закладываться на то, что эти адреса нельзя считать неконфликтующими. Выглядеть это будет следующим образом:
{
if ((p0+N) < p1) || ((p1+N) < p0)
{
int * __restrict rp0 = p0;
int * __restrict rp1 = p1;
for (i=0; i<N; i++)
rp0[i] = rp1[i] + 1;
}
else
for (i=0; i<N; i++)
p0[i] = p1[i] + 1;
}
Важно, что первично будет происходить сравнение адресов на предмет того, что они не пересекаются —
правая граница p0 меньше левой границы p1 и правая граница p1 меньше p0.
Если условие этого выражения истинно, то компилятор создаст новые указатели со спецификатором __restrict,
которым присвоит старые указатели p0 и p1 и будет выполнять цикл с ними.
Это позволит забрасывать чтения из rp1 на всем диапазоне адресов цикла над записями в rp0.
В случае, если проверяемое выражение оказалось ложью, то будет выполняться обычный первоначальный цикл.
Расчет здесь сделан на то, что чаще адреса будут независимы, и компилятор не зря подготовил дополнительный код и делает дополнительную проверку.
Если снять профиль со счётчиками при выполнении такой процедуры и в профиле будет видно, что мы часто попадаем в вариант, где есть конфликт адресов,
то рекомендуется выключить режим RTMD с помощью опции -fno-loop-rtmd.
Минусом этого подхода является необходимость попарного сравнения всех конфликтующих адресов, например,
для 8 чтений и 6 записей потребуется строить 96 сравнений.
Последний вариант разрыва конфликтов в динамике является аппаратно-программным. Он уже упоминался при описании спекулятивности по данным. Механизм построен на использовании аппаратной таблицы DAM. Рассмотрим пример:
{
int * p0 = param0;
int * p1 = param1;
...
*p0 = a;
b = *p1 * 14;
...
}
В этом примере нельзя поднять операцию чтения из *p1 и зацепленную за неё операцию умножения выше записи в *p0.
Но с использованием аппаратной таблицы DAM это становится возможно.
Компилятор может выполнить спекулятивно операцию чтения и умножения. При этом чтение будет выполняться с тегом mas=0x4, это запирающее чтение.
Оно поместит адрес чтения в аппаратную таблицу.
После чтения выполнится запись в *p0, над которой мы спекулятивно выполнили чтение.
При этом запись будет выбивать из аппаратной таблицы, куда был занесен адрес при запирающем чтении, любые адреса,
пересекающиеся с этой записью, даже пересекающиеся частично.
После записи компилятор поместит проверочное чтение с тегом mas=0x3.
Это чтение будет проверять, остался ли адрес, внесенный в таблицу, запирающим чтением.
Если адрес остался, то чтение и запись никак не пересекались, и перенос был правомерным.
Если же записи не осталось в аппаратной таблице, будет произведен переход на компенсирующий код, в котором придется заново производить умножение.
При этом появятся дополнительные штрафы при переходе на компенсирующий код и возврат из него.
Также операция проверочного чтения удалит из таблицы проверенную строку.
В этой технике, как и в RTMD, сделан расчет на то, что конфликта адресов между чтением и записью при исполнении
чаще всего нет, и в компенcирующий код мы будем попадать редко.
Если в профиле со счётчиками видно, что мы часто попадаем в компенсирующий код, то рекомендуется отключить спекулятивность
по данным опцией -fno-dam.
Для лучшего понимания пример, описанный выше, проиллюстрирован на рис. Аппаратная поддержка, таблица DAM.
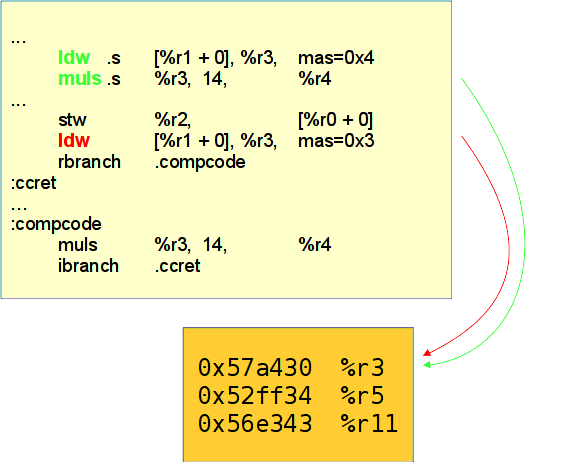
Аппаратная поддержка, таблица DAM¶
Подытоживая раздел с разрывом конфликтов по памяти, можно еще выделить несколько опций, которые могут пригодиться программистам.
Это опции:
-fwhole- умощняет межпроцедурный анализ;-frestrict-allавтоматически проставляет спецификатор__restrictна все указатели;-frestrict-paramsавтоматически проставляет спецификатор__restrictна указатели-параметры процедур.
6.6. Предварительная подкачка данных¶
Чтение из памяти - операция, имеющая различную длительность.
Разница обусловлена наличием аппаратных кэш-памятей, ускоряющих этот доступ.
Без них время доступа было бы одинаково долгим, порядка 100-200 тактов.
Кэши-памяти, как правило, устроены иерархически: от небольших кэшей с быстрым доступом до больших кэшей с медленным доступом.
Маленький кэш первого уровня L1 расположен ближе всего к вычислительным ресурсам и обеспечивает наименьшее время доступа.
При планировании операций компилятор по-умолчанию считает, что операция чтения всегда попадает в кэш данных первого уровня.
Проблема в том, что кэш L1 удерживает далеко не все данные, за которыми обращается программа.
При каждом кэш-промахе возникает блокировка. Её длительность варьируется:
L2 кэше;L3 кэше;Такты во время блокировки не тратятся на что-либо полезное, в результате получается низкая скорость исполнения операций за такт. Такие блокировки для VLIW архитектур являются очень критичными. Для OOOSS блокировки являются менее критичными, так как они могут совмещаться в рамках окна переупорядочивания операций для нескольких промахнувшихся операций чтения. Также для современных OOOSS реализован механизм автоматической подкачки линейных данных в кэш-память, основанный на обнаружении линейных паттернов доступа.
Для решения проблемы с блокировками конвейера, вызванными операциями чтения, в архитектуре «Эльбрус» предусмотрено несколько методов:
Ациклические участки кода:
совмещение блокировок;
ограничение на простановку маловероятных чтений в спекулятивный режим.
Цикловые участки кода:
cовмещение блокировок в конвейеризированных циклах;
выявление регулярных чтений, предподкачка с помощью
prefetch (ld->empty);использование аппаратно-программного механизма для подкачки линейных данных.
Так как это пособие является практическим, описание совмещения блокировок компилятором и простановки маловероятных чтений в спекулятивный режим будет пропущено.
Встроенная функция __builtin_prefetch() позволяет заблаговременно подкачать данные в кэш-память.
Подкачивается целая порция кэш-строк - 64 байта.
Синтаксис:
__builtin_prefetch(addr, rw, locality)
addr - адрес памяти для предподкачки.
rw (0..1) - подкачка для чтения либо записи.
0 - (умолчание) подкачка для чтения.
1 - подкачка записи, означает простановку признака эксклюзивности подкачанной
кэш-строке (зарезервировано для версий системы команд >5).
locality (0..3) - уровень темпоральной локальности (ожидание переиспользования).
3 (умолчание) означает сохранение во всех кэшах.
0 - можно выкидывать из кэша сразу после использования.
Locality фактически используется для указания уровня кэш-памяти подкачки.
При использовании __builtin_prefetch() в ассемблере можно увидеть спекулятивное чтение, но не в регистр назначения, а в empty:
ld .s [addr, offset] →%empty, mas=...
Уровень кэш-памяти регулируется параметром mas:
0x0 (умолчание) - заводить везде
0x20 - не заводить в L1$
0x40 - не заводить в L1$ и L2$
0x60 - не заводить в кэшах (для подкачки не используется)
В обычных циклах компилятор умеет находить регулярно зависящие от индуктивности чтения и
добавлять опережающие на dist итераций операции ld → empty.
Когда компилятор не смог или побоялся префетчить данные, это стоит сделать вручную.
for (i=0; i<N; i++)
{
{ // block }
s += a[i];
{ // block }
}
Например, так:
for (i=0; i<N; i++)
{
{ // block }
s += a[i];
__builtin_prefetch(&(a[i+dist]));
{ // block }
}
Для расчета dist компилятор использует округленное в большую сторону отношение времени доступа в память и оценки времени планирования итерации цикла.
dist вычисляется следующим образом:
dist = Lat (ld ← mem) / T (iter)
Для использования предподкачки в циклах следует использовать комбинацию префетчей.
Пусть
a[ i ] - 0-линейное чтение
b[ a[ i ] ] - 1-линейное чтение
с[ b[ a[ i ] ] ] - 2-линейное чтение
Компилятор умеет обнаруживать и строить предподкачку для n-линейно-регулярных чтений (на практике n<=3). Общий принцип - строится n подкачек:
a[ i+(n+1)*dist ]
b[ a[ i+(n)*dist ] ]
c[ b [ a[ i+(n-1)*dist ] ] ]
…
В коде это может выглядеть следующим образом:
for (i=0; i<N; i++)
{
{ // block }
s += p->values->coords->x;
p++;
{ // block }
}
С использованием префетча:
for (i=0; i<N; i++)
{
{ // block }
s += p->values->x;
p++;
__builtin_prefetch(&((p+3*dist)->values));
__builtin_prefetch(&((p+2*dist)->values->coords));
__builtin_prefetch(&((p+ dist)->values->coords->x));
{ // block }
}
Для увеличения производительности в случае чтения в цикле по линейно изменяющимся адресам (a[i], b[k*i], (p++) и т.п.) в архитектуре ``Эльбрус`` реализован механизм асинхронного доступа к элементам массива. Суть его состоит в следующем: доступ к массивам описывается особым образом в виде кода асинхронной программы. Она состоит только из операций **fapb*. Операции fapb запускаются по циклу в независимом конвейере, пополняя буферы упреждающих данных для разных массивов. При этом основной поток исполнения забирает данные из этого буфера операциями mova (вместо запуска операций чтения).
Преимущества, предоставляемые механизмом асинхронного доступа к массивам:
вместо операции чтения, занимающей ALU, используется операция mova, занимающая отдельный канал, что освобождает в широкой команде место под арифметическую операцию;
блокировки из-за отсутствия данных существенно уменьшаются, т.к. операции доступа к памяти, имеющие непредсказуемую длительность, выполняются асинхронно и не блокируют основной поток исполнения операций. При этом операции mova имеют фиксированную длительность.
В одной широкой команде можно исполнить до 4 операций чтения из буфера APB. Программисту в редком случае может понадобиться разбираться в тонкостях работы APB. В этом методическом пособии данный вопрос пропущен. Достаточно понимать, что механизм APB приносит существенную пользу. APB можно применять:
при отсутствии вызовов функций в цикле - механизм не допускает сохранения и восстановления при вызове;
при выровненности адресов; требование снято для форматов 2, 4 и 8 в версии v5 системы команд; снято для формата 16 в версии v6 системы команд.
Также отдельно стоит выделить случаи, когда механизм APB эффективен:
при достаточно большом числе итераций;
при отсутствии зависимостей с записями между итерациями, либо при достаточно большой дистанции зависимости.
при инкременте адреса <32b apb более эффективен, чем при больших инкрементах;
На основании соображений эффективности компилятор может отказываться от применения apb для конкретных циклов.
Существуют также ресурсные ограничения применения apb в цикле:
число различных массивов не может превышать 32;
число различных инкрементов адреса не может превышать 8;
порция данных, читаемая из одного массива в рамках одной итерации, не может превышать 32 байта; если требуется большее количество данных (например, читается массив структур, либо к циклу применена раскрутка), компилятор разбивает их на порции <32b и считает различными массивами
Для управления предподкачкой в арсенале программиста есть следующие опции компилятора:
-fprefetch- включает применение предподкачки в циклах;-fcache-opt- включает применение совмещения блокировок в конвейеризированных циклах;-fno-apb- выключает применение apb;-faligned(также входит в состав-ffast) - разрешение компилятору предполагать выровненность операций обращения к памяти по формату. Является фактически необходимой для возможности применения apb для чтений формата больше 1 байта, в версиях системы командV1-V4. Опция -faligned также влияет на работу других оптимизаций, и при этом возлагает на пользователя ответственность за выровненность обращений: компиляция с опцией -faligned программ с нарушением выровненности может приводить к ошибкам. Для проверки нарушения выровненности рекомендуется использовать опцию -faligned-check, по которой включается аппаратный контроль выравнивания обращений к памяти - невыровненное обращение к памяти вызовет сигнал SIGBUS.